

Sciences & Société
Soutenance de l'Habilitation à Diriger des Recherches en sciences : Omar HASAN
Soutenance est publique
Maître de conférences : Omar HASAN
Laboratoire INSA : LIRIS
Rapporteurs :
- M. Nicolas ANCIAUX Directeur de recherche, Inria Saclay
- M. François CHAROY Professeur, Université de Lorraine, Inria Nancy
- M. François TAIANI Professeur, Université de Rennes 1, Inria Rennes
Jury :
Examinateurs :
- Mme Elisa BERTINO Professeur, Purdue University
- M. Lionel BRUNIE Professeur, INSA Lyon
- M. Stelvio CIMATO Professeur, Università degli Studi di Milano
- M. Christophe GARCIA (invité) Professeur, INSA Lyon
- Mme Parisa GHODOUS Professeur, Université Claude Bernard Lyon 1
- M. Andrew MARTIN Professeur, University of Oxford
Informations complémentaires
-
Salle 501.337, bâtiment Ada Lovelace
Mots clés

Sciences & Société
Soutenance de thèse : Méghane DECROOCQ
Développement d’une méthode de modélisation et maillage de réseaux artériels basée sur la ligne centrale pour les études hémodynamiques des pathologies cérébrovasculaires / Development of a centerline-based arterial network modeling and meshing framework for hemodynamic studies of cerebrovascular pathologies
Doctorante : Méghane DECROOCQ
Laboratoire INSA : LIRIS
Ecole doctorale : ED512 Infomaths
La dynamique des fluides numérique (CFD) est une technique qui fournit des informa- tions précieuses sur l’écoulement du sang à partir de la géométrie vasculaire, permettant de comprendre, de diagnostiquer et de prévoir l’issue des maladies vasculaires. Cependant, la résolution des images médicales actuelles n’est pas satisfaisante, et il est encore difficile d’extraire les vaisseaux sanguins, en particulier ceux dont la géométrie est complexe, comme les réseaux d’artères cérébrales. Dans cette thèse, nous avons proposé un cadre en deux étapes pour produire des maillages prêts pour la CFD à partir d’une représentation simplifiée des réseaux vasculaires par leurs lignes centrales. Dans la première étape, afin de pallier aux défauts de la représentation basée sur les lignes centrales (dispersées, bruitées), une étape de modélisation a été introduite pour reconstruire un modèle anatomiquement réaliste à partir de connaissances a-priori sur les vaisseaux et les géométries des bifurca- tions. Ensuite, une étape de maillage a été développée pour créer un maillage volumique de haute qualité avec des cellules hexaédriques structurées et orientées vers l’écoulement, répondant aux exigences de la CFD. Grâce à ce logiciel, nous avons créé une base de donnée de maillages pour la CFD de réseaux entiers d’artères cérébrales, qui peut être utilisé pour l’évaluation de dispositifs médicaux et les études hémodynamiques. Ce logiciel contribue à combler des lacunes des méthodes de maillage actuelles et permet la construction de bases de données de larges réseaux artériels cérébraux pour la CFD.
Informations complémentaires
-
Salle de conférence de la bibliothèque universitaire, Université Lyon 1 (Villeurbanne)

Sciences & Société
Soutenance de thèse : Alaa ALHAMZEH
Language Reasoning by means of Argument Mining and Argument Quality
Doctorante : Alaa ALHAMZEH
Laboratoire INSA : LIRIS
Ecole doctorale : ED512 Infomaths
Understanding of financial data has always been a point of interest for market participants to make better informed decisions. Recently, different cutting-edge technologies have been addressed in the Financial Technology (FinTech) domain, including data analysis, opinion mining and financial document processing. In this thesis, we are interested in analyzing the arguments of financial experts with the goal of supporting investment decisions. Although various business studies confirm the crucial role of argumentation in financial communications, no work has addressed this problem as a computational argumentation task. In other words, the automatic analysis of arguments. Focusing on this issue, this thesis presents contributions in the three essential dimensions of theory, data, and evaluation. First, we propose a method for annotating the structure of the arguments stated by company representatives during the earnings conference calls. The proposed scheme is derived from argumentation theory at the micro-structure level of discourse. We further conducted the corresponding annotation study and published the first financial dataset annotated with arguments: FinArg. Moreover, we further investigate the question of evaluating the quality of arguments in this genre of text. To tackle this challenge, we suggest using two levels of quality metrics, considering both the Natural Language Processing (NLP) literature of argument quality and the financial era peculiarities. We have also enriched the FinArg data with our quality dimensions to produce the FinArgQuality dataset. In terms of evaluation, we validate the principle of ensemble learning on the argument identification and argument unit classification tasks. We show that combining a traditional machine learning model along with a
deep learning one, via an integration model (stacking), improves the overall performance, especially in small dataset settings. Although argument mining is mainly a domain-dependent task, to this date, the number of studies that tackle the generalization of argument mining models is still relatively small. Therefore, using our stacking approach and in comparison to the transfer learning model of DistilBert, we address and analyze three real-world scenarios concerning the model robustness over unseen domains and variant topics. In addition, with the aim of the automatic assessment of argument strength, we have investigated and compared different (refined) versions of Bert-based models. Consequently, we managed to outperform the baseline model by 13 ± 2% in terms of F1-score through integrating Bert with encoded categorical features. Beyond our theoretical and methodological proposals, the dimensions of argument quality assessment, annotated corpora, and evaluation approaches are publicly available, and can serve as strong baselines for future work in both FinNLP and computational argumentation domains. Hence, directly exploiting this thesis, we described and proposed to the community, within the framework
of the NTCIR-17 conference, a new task/challenge, the FinArg-1 task, relating to the analysis of financial arguments. We also used our proposals to respond to the Touché challenge at the CLEF 2021 conference. Our contribution was selected among the « Best of Labs ».
Informations complémentaires
-
Salle de créativité 202 - (Bibliothèque Marie Curie) - Villeurbanne

Sciences & Société
Soutenance de thèse : Léon Victor
Learning-Based Interactive Character Animation Edition
Doctorant : Léon Victor
Laboratoire INSA : LIRIS
Ecole doctorale : ED512 Informatique Et Mathématiques de Lyon
La principale méthode utilisée pour animer un personnage virtuel consiste à éditer le mouvement d’un squelette, sur lequel un modèle sous forme de maillage sera appliqué et déformé au besoin. Pour convaincre le spectateur, le mouvement d’un personnage doit respecter de nombreuses règles implicites, comme le modèle physique qui régit son monde ou les limites de sa morphologie. Ce faisant, il doit aussi rendre explicite l’action réalisée, et laisser transparaître l’état émotionnel du personnage. La subtilité de ces contraintes rend la création d’animation difficile et la production d’une animation réaliste et/ou plaisante repose fortement sur les connaissances, l’expérience et minutie de l’animateur. La démocratisation des techniques de capture de mouvement (Motion Capture, ou MoCap) permet de produire de plus en plus de données de mouvements tirés du monde réel, qui portent intrinsèquement des informations sur ces contraintes. Les travaux présentés dans cette thèse proposent d’exploiter ces données à l’aide de méthodes récentes d’apprentissage automatique, utilisant les réseaux de neurones pour fournir de nouveaux outils aux artistes animateurs.
Informations complémentaires
-
Salle C5 du bâtiment Nautibus de l'UCBL (Villeurbanne)
Sciences & Société
Soutenance de thèse : Luca VEYRIN-FORRER
Explaining machine learning models on graphs by identifying hidden structures built by GNNs
Doctorant : Luca VEYRIN-FORRER
Laboratoire INSA : LIRIS
Ecole doctorale : ED512 Infomaths
La dernière décennie a vu une énorme croissance dans le développement de techniques basées sur les réseaux de neurones profonds pour les graphes. Les réseaux de neurones sur graphes (GNNs) se sont avérés les plus efficaces pour de nombreux problèmes d'apprentissage automatique de graphes tels que les méthodes de noyaux. Cependant, le fonctionnement interne des modèles GNN reste opaque, ce qui constitue un obstacle majeur à leur déploiement, soulevant des questions d'acceptabilité sociale et de fiabilité, limites qui peuvent être surmontées par l'explication du fonctionnement interne de tels modèles. Dans cette thèse, nous étudions le problème de l'explicabilité des GNNs. Notre contribution principale, INSIDE, vise à extraire les règles d'activation dans les couches cachées du modèle pour comprendre quels descripteurs et caractéristiques de graphes ont été automatiquement extraits des graphes. Le défi consiste à fournir un petit ensemble de règles qui couvrent tous les graphes d'entrée. Nous proposons un domaine de motifs subjectif pour résoudre cette tâche. Nous proposons l'algorithme INSIDE qui est efficace pour énumérer les règles d'activation dans chaque couche cachée. Les règles d'activation peuvent ensuite être utilisées pour expliquer les décisions du GNN. l'étude expérimentale montre des performances très compétitives par rapport aux audres méthodes de l'état de l'art. Cependant, les règles d'activation ne sont pas interprétables. Nous proposons d'interpréter ces règles en identifiant un graphe entièrement plongé dans le sous-espace associé à chaque règle. La méthode DISCERN que nous avons mise mise au point est basée sur une recherche arborescente de type Monte Carlo dirigée par une mesure de proximité entre le plongement du graphe et la représentation interne de la règle. Les graphes ainsi obtenus sont réalistes et pleinement compréhensibles par l'utilisateur final.
Informations complémentaires
-
Salle 501.337 - Amphi FC, Bâtiment Ada Lovelace (Villeurbanne)

Recherche
« Il est possible d’aller vers une IA plus frugale »
« Faire aussi bien (voire mieux) avec moins de ressources » : ce pourrait bien être la maxime préférée de Stefan Duffner, enseignant-chercheur au laboratoire LIRIS1. Spécialiste de l’apprentissage et de la reconnaissance des formes au sein de l’équipe Imagine2, il explore une approche de l’Intelligence Artificielle (IA) plus frugale. Comment faire de l’IA robuste, sécurisée et fiable avec moins de données ? Comment relever le défi de la sobriété dans un domaine tenaillé par une course à la performance permanente ? Quel degré d’erreurs est-il acceptable pour un système à qui l’on demande de prendre des décisions pour nous-même ? Stefan Duffner propose d’explorer un concept qui encourage une approche de compromis, entre performances et impacts sur l’environnement. Explications.
Pourquoi, de tous les outils du numérique, l’intelligence artificielle devrait-elle prendre le pli d’une certaine frugalité ou sobriété ?
Derrière le terme « intelligence artificielle » se cache un monde très vaste. Pour ma part, je m’intéresse à l’apprentissage automatique et aux réseaux de neurones profonds, appelé « deep-learning », qui sont des méthodes qui régissent nos principaux usages de l’intelligence artificielle. Ces dernières années, les outils faisant appel à des IA, se sont largement démocratisés, au moyen d’appareils embarqués et de données massivement exploitées. Si l’utilisation de ces données volumineuses permet d’avoir des modèles très précis, il est désormais reconnu qu’elle présente de lourdes conséquences sur le plan environnemental, notamment en matière de consommation d’énergie. Aussi, cette exploitation de données massives va souvent de pair avec des calculs de plus en plus complexes et lourds. Une autre part de la consommation énergétique de l’IA vient de l’apprentissage. Pour qu’un modèle d’intelligence artificielle fonctionne, il a besoin d’être entraîné, d’apprendre. Souvent déployée sur des data centers de grande envergure, cette activité peut s’avérer très gourmande en énergie. Ces approches actuelles, qui ne tiennent pas compte des ressources limitées de la planète, ne sont plus tenables. C’est pour cette raison qu’une partie de la communauté scientifique appelle à plus de frugalité dans l’utilisation des intelligences artificielles, en étudiant d’autres approches plus sobres, tout au long du cycle de développement de l’IA.

Concrètement, quels leviers peuvent être actionnés pour que l’intelligence artificielle soit plus « frugale » ?
Le but, c’est de faire plus léger. Aujourd’hui, beaucoup de modèles sont surdimensionnés et consomment beaucoup plus d’énergie que le besoin le requiert. Il y a beaucoup d’approches pour faire plus « frugal » en matière d’intelligence artificielle et la communauté scientifique commence à s’intéresser notamment à la réduction de la complexité des modèles, en utilisant moins de données ou en les « élaguant ». Il y a aujourd’hui, une surenchère des réseaux de neurones car c’est le système fournissant les résultats les plus performants et efficaces. Cependant, il existe de nombreux usages pour lesquels un apprentissage un peu moins efficace, moins énergivore et plus explicable comme les modèles probabilistes, pourrait convenir. Et puis, concernant les autres leviers, il y a la dimension du matériel, du réseau et du stockage des données qui mériterait d’être repensée pour des IA plus sobres. Je dis « sobre », car il me semble que c’est un terme à différencier de « frugal ». La frugalité invite à faire mieux avec moins, alors qu’il me semble que la sobriété implique de remettre en question les besoins, à l’échelle sociologique, ce qui n’est pas de mon domaine de chercheur en informatique.
Donc, d’après ce que vous laissez entrevoir, l’IA frugale, ça n’est pas vraiment pour tout de suite. Quels sont les freins ?
J’identifie au moins deux freins majeurs. D’abord, un frein technique. Faire de l’IA frugale implique de trouver le bon compromis entre sécurité, robustesse et réponse au besoin. Les deux premières propriétés sont complètement inhérentes à notre usage de l’intelligence artificielle : nous ne voulons pas utiliser d’IA qui fasse de graves erreurs et qui soit sujette aux attaques malicieuses. Parfois, en diminuant les modèles pour gagner en économie d’énergie, on diminue la robustesse. Prenons l’exemple de la voiture autonome : nous ne voulons certainement pas diminuer la robustesse de l’IA qui contrôle la voiture automatique, et que celle-ci confonde un vélo et un piéton. Pour lui faire apprendre à différencier les situations, cette IA a « appris », à travers une multitude de situations différentes. Il sera donc difficile dans cette situation d’alléger le modèle car le seuil de tolérance doit être très bas pour éviter la moindre catastrophe. Bien sûr, on peut questionner le besoin de développer des voitures autonomes, mais c’est un autre débat… L’autre frein majeur pour le développement d’une IA plus frugale, c’est qu’elle implique des compétences dans plusieurs domaines, ce qui réduit le champ des spécialistes pouvant s’impliquer dans cette mouvance. C’est d’ailleurs ce qui m’a motivé à faire un projet avec la SATT Pulsalys3 pour développer un service, facile d’utilisation destiné aux ingénieurs, data-scientists ou à des entreprises qui souhaiteraient s’investir dans la réduction de modèles, sans pour autant en être spécialistes. Nous sommes encore en train de travailler sur un prototype qui ne devrait pas tarder à voir le jour.
Il y a un vrai débat entre les approches dites « green IT » et « IT for Green ». Les terminologies sont proches, pourtant, les démarches ne sont pas les mêmes. Comment y voir plus clair ?
Effectivement, il y existe un vrai débat entre ces approches, qui peuvent être complémentaires. La première prévoit de minimiser l’impact négatif des opérations et des équipements sur l’environnement. L’autre est une démarche qui utilise le numérique dans un objectif de réduction de l’empreinte écologique. Pour ma part, je crois que les intelligences artificielles sont encore trop largement utilisées pour créer des besoins dont l’utilité pourrait être remise en question. Cela est dû au déploiement massif de l’IA ces dernières années, lui-même rendu possible par la disponibilité des ressources de calcul et le matériel disponible, assez bon marché. Jusqu’à aujourd’hui, il est facile d’investir dans l’IA, grâce à des financements. Il ne faut pas oublier que c’est un domaine encore jeune, et que les solutions pour faire plus frugal, ne sont pas encore à la portée de tous. Sur le papier, j’ai le sentiment qu’il y a beaucoup de volonté pour faire « plus vert », mais dans les entreprises, la décision est difficile : utiliser une IA plus « verte » coûte souvent plus cher. Alors que développer un outil d’IA pour faire « plus vert », est un projet plus facilement défendable devant des financeurs. C'est aussi un domaine qui manque encore de règlementation. Nous pourrions imaginer que l’utilisation d’une IA soit soumise à des obligations d’économie d’énergie : ces règles existent pour le chauffage, pourquoi pas avec une IA ?
L’INSA Lyon lance la semaine du numérique responsable
Envie d’explorer le sujet de l’intelligence artificielle frugale plus en détail ?
Stefan Duffner sera présent lors de la première édition de la semaine du numérique responsable qui se tiendra du 3 au 7 avril, à l’INSA Lyon. À travers des conférences ouvertes à tous, avec la participation de chercheurs, d’étudiants ou de partenaires économiques et académiques, l’INSA Lyon souhaite pousser à la réflexion autour de la transition numérique lors d’une semaine dédiée.
=> Découvrir le programme
[1] Laboratoire d'InfoRmatique en Image et Systèmes d'information (UMR 5205 CNRS / INSA Lyon / Université Claude Bernard Lyon 1 / Université Lumière Lyon 2 / École Centrale de Lyon)
[2] Computer vision, Machine Learning, Pattern recognition
[3] Créée en 2014, La Société d’Accélération du Transfert de technologies (SATT) Pulsalys du site Lyon et Saint Étienne a pour mission de mutualiser les moyens et compétences des établissements de recherche publique de l’écosystème lyonnais et stéphanois en vue d'accélérer le transfert de technologies issu de leurs laboratoires.

Recherche
Crypto-prêts : de la tradition de village à la blockchain
Dans de nombreux pays émergents, il est difficile d’entreprendre pour les personnes disposant de faibles revenus. La plupart des prêts accordés par les banques traditionnelles étant des prêts garantis, les termes et conditions ne sont pas toujours faciles à remplir pour les emprunteurs. C’est le cas en Indonésie, le pays d’origine de Wisnu Uriawan, où ces barrières empêchent certains de créer ou de développer une activité génératrice de revenus.
Docteur de l’INSA Lyon depuis quelques mois, il a passé ses quatre années de doctorat au LIRIS1 à étudier des solutions d’émancipation financière par la blockchain. En s’inspirant de modèles informels de prêts traditionnels de villages africains, le désormais docteur a travaillé à mettre en place une plateforme, « TrustLend », pour faire se rencontrer emprunteurs, recommandataires et prêteurs. Il a récemment obtenu le prix Mahar Schützenberger, une récompense franco-indonésienne pour la qualité de ses travaux de thèse.
 Favoriser l’émancipation et l’inclusion financière
Favoriser l’émancipation et l’inclusion financière
Acheter du matériel agricole, une machine à coudre pour lancer un micro-business, financer une opération chirurgicale ou des frais de scolarité… Pour les citoyens de certains pays émergents, il est parfois difficile de mobiliser de l’épargne pour faire évoluer son activité et améliorer son niveau de vie. Pour pallier cette situation, des systèmes de micro-crédits de particulier à particulier ont vu le jour. Aussi, le développement exponentiel de la technologie blockchain et des cryptomonnaies dans les pays émergents semblent également avoir trouvé des applications dans le secteur financier : les prêts peer-to-peer sur la blockchain pourraient représenter un volume estimé à près d’un billion de dollars d’ici 2050. Témoin de la situation dans son pays, Wisnu Uriawan a rejoint le LIRIS il y a quatre ans avec cette idée : rendre accessible le système de prêt de pair à pair grâce à la technologie blockchain et aux smart contracts.
Redéfinir la fiabilité d’un emprunteur grâce à la communauté
En s’inspirant d’un système informel de prêt au sein de certaines communautés, Wisnu a imaginé un fonctionnement permettant de remplacer tout ou partie des garanties bancaires exigées traditionnellement par les organismes prêteurs pour les remplacer par un mécanisme de réputation sociale. Comme dans certains villages africains, l’engagement de la communauté ferait office de soutien au demandeur. « Mes travaux de thèse proposent que la fiabilité des emprunteurs soit utilisée comme alternative dans les demandes de prêts afin que les emprunteurs ne soient plus accablés par des garanties ou garants. La principale problématique était de réussir à calculer de manière fiable, cette fiabilité », explique le docteur.
Wisnu et ses encadrants de thèse ont ainsi développé le modèle « LAPS », pour « Loan risk Activity, Profile and Social recommendation2 », permettant de calculer un « score de fiabilité » pour chaque emprunteur. « Nous introduisons la notion de recommandation sociale en soutien à l’emprunteur en fonction de certaines variables telles que le risque de prêt, son activité, son profil ou son projet. Ce score peut aider à convaincre les prêteurs et les investisseurs de lui accorder des prêts avec peu ou pas de garanties classiques. »
Un prêt sans banque, grâce à la blockchain et aux smart contracts
Une fois la fiabilité de l’emprunteur reconnue par les pairs, comment contractualiser la transaction, sans l’intervention d’un organisme bancaire ? « Les smart contracts, ou contrats intelligents, sont des programmes codés alimentés par la blockchain. Ils peuvent faire office d’intermédiaires entre les pairs de manière sécurisée et où toutes les règles classiquement convenues peuvent être appliquées », explique Wisnu. Comptant sur les vertus de traçabilité et de partage de données de la blockchain, les conditions et termes du smart contract sont ainsi visibles par tous, obligeant à la bonne exécution du contrat. L’autre avantage du smart contract réside dans le coût d’exécution : en évitant une grande partie des intermédiaires, le processus de contractualisation bénéficie de coût réduit ; un avantage notable par rapport aux crédits classiques dont le coût est relativement élevé. Reste à lever l’un des freins majeurs du système : le jugement lors d’un litige, avis duquel la blockchain ne pourrait pas se substituer à l’humain.
Une plateforme qui fait se rencontrer emprunteurs et prêteurs
C’est ainsi que Wisnu Uriawan a souhaité voir ces années de travaux sur la blockchain et les smart contracts se concrétiser : en développant une application dédiée à la rencontre entre emprunteurs et prêteurs. Intitulée « TrustLend », le logiciel, s’il est prêt à être déployé, doit encore attendre certaines évolutions de la régulation. « Je viens d’un pays émergent où j’imagine une application très vertueuse de ce système. L’idée est d’aider des gens dans le monde, pas de faire du profit. Je suis rentré à Java désormais, et j’ai apporté cette idée dans mes valises. Je suis persuadé que, pour les emprunteurs, ce système sera très utile, par exemple pour un agriculteur qui ne pourrait pas acheter son tracteur comptant. »
La blockchain, qui se trouve également être au service de la finance participative, le crowdfunding, pourrait trouver sa place entre finance, anthropologie et informatique. « La blockchain a beaucoup à apporter au secteur financier en matière de transparence des transactions. Si l’on ajoute à cela la confiance accordée par la communauté, on peut espérer créer un cercle vertueux où plus vous avez fait preuve de fiabilité et plus vous obtenez un score recommandable par la communauté. C’est une autre façon de penser les prêts financiers et l’argent en général. »
[1] Laboratoire d’Informatique en Images et Systèmes d’Informations (CNRS / INSA Lyon / Université Claude Bernard Lyon 1 / Université Lumière Lyon 2 / École Centrale de Lyon)
[2] Risque de crédit, Activité, Profil, et Recommandation sociale
Sciences & Société
Soutenance de thèse : Théotime GROHENS
Ride the Supercoiling: Evolution of Supercoiling-Mediated Gene Regulatory Networks through Genomic Inversions
Doctorant : Théotime GROHENS
Laboratoire INSA : LIRIS
Ecole doctorale : ED512 InfoMaths
Evolution is often considered an unpredictable process, as genetic mutations happen at random.
But the fixation of mutations is not completely arbitrary, as mutations need to pass the sieve of natural selection to be retained.
In particular, the beneficial or deleterious character of a mutation can depend on the genetic background in which it happens, an effect called epistasis.
In this work, I study a particular kind of epistatic interactions in bacteria: the interplay between mutations in the mechanisms regulating DNA supercoiling -- the level of over- or under- winding of DNA -- and genomic rearrangements. I present _EvoTSC_, a mathematical and computational model of DNA supercoiling tailored to study the mutual interaction between gene transcription and DNA supercoiling (the _transcription-supercoiling coupling_ or TSC), and integrated into a full-fledged evolutionary simulation.
I first validate the model by showing that evolution can leverage this coupling to evolve gene regulatory networks that are able to tune gene expression levels in response to environmental perturbations, by changing only the relative positions of the genes through genomic inversions.
I then show that, in _EvoTSC_ as well as in the evolutionary simulation platform _Aevol_, introducing supercoiling mutations does not seem to speed up evolution, indicating that the evolutionary relevance of epistatic interactions might be not as important as initially thought.
Using _EvoTSC_, I additionally show that the TSC can lead some genes to be activated by an excess of positive supercoiling, providing a plausible mechanism to explain the similar behavior observed in many bacterial genes. Finally, I characterize the structure of these supercoiling-mediated gene regulatory networks, showing that they cannot be reduced to local pairwise interactions.
Interaction with many neighboring genes can indeed be needed to regulate gene expression through supercoiling, providing a possible explanation to the evolutionary conservation of gene syntenies.
Informations complémentaires
-
Amphithéâtre 501-337, Bâtiment Ada Lovelace (Villeurbanne)

Recherche
« L’inclusion des minorités doit être une priorité pour l’IA »
Industrie, médecine, applications de rencontres ou même justice : l’intelligence artificielle (IA) inonde divers aspects de notre vie quotidienne. Seulement, certaines erreurs plus ou moins graves, sont régulièrement relevées dans le fonctionnement de celles-ci. En cause ? Des biais de représentativités présents dans les jeux de données.
Virginie Mathivet, ingénieure INSA du département informatique (2003) et docteure du laboratoire Liris1, est engagée sur la question. Pour l’auteure et conférencière, un maître-mot pour que l’IA ne soit pas un outil de duplication des discriminations déjà vécues dans la vie réelle par certaines minorités : la diversité. Récemment nommée experte IA de l’année 2022, Virginie a partagé son savoir à la communauté dans le cadre de « la semaine des arts et des sciences queer » organisée par l’association étudiante Exit+. Elle alerte sur l’extrême nécessité de porter une attention particulière à l'inclusion dans l’intelligence artificielle. Interview.
On connaît l’importance de la diversité pour faire une société plus égalitaire ; pourquoi est-elle aussi importante dans les jeux de données utilisées par les IA ?
Les intelligences artificielles sont des machines apprenantes : grâce à des bases de données, que l’on appelle des « datasets », des modèles sont fabriqués par des développeurs dans un but précis, par exemple pour détecter des défauts sur les chaînes de fabrication industrielles et pour lesquelles ils donnent de très bons résultats. Cependant, ces dernières années on a vu exploser les applications entraînant des prises de décisions sur les humains : l’accès à un crédit, le recrutement, des décisions de justice… On a aussi vu que ces IA étaient capables d’erreurs systématiques. On se souvient du logiciel de recrutement discriminant d’Amazon dont l’objectif était de faire économiser du temps aux ressources humaines en étudiant les candidatures les mieux notées par la machine. Il s’est avéré que l’algorithme sous-notait les profils féminins fréquemment car les jeux de données utilisés pour modéliser le logiciel s’appuyaient sur les CV reçus les dix dernières années, dont la plupart étaient des candidatures masculines. C’est ce que l’on appelle « un biais » : la machine ne fait jamais d’erreur aléatoire ; elle répète les biais -conscients ou inconscients- que les expérimentateurs ont commis en choisissant les données. Sans diversité, qu’elle soit de genre, culturelle, de génération, l’IA restera une extension des inégalités vécues dans la vie réelle.
Avez-vous d’autres illustrations de ce risque que représente le manque de diversité dans les jeux de données ?
Un exemple assez parlant est celui du système de reconnaissance faciale utilisée par les iPhones. La première version de FaceID n’était pas capable de reconnaître les propriétaires asiatiques car le dataset initial ne comptait pas assez de visages de ce type et l’algorithme n’avait tout simplement pas appris à les reconnaître ! Mais il existe des exemples aux conséquences beaucoup plus graves comme les systèmes de détection automatique des cancers de la peau : l’intelligence artificielle est tout à fait capable de reconnaître des mélanomes sur les peaux blanches, beaucoup moins sur les peaux foncées. Cela occasionne des problèmes d’accès aux soins considérables, en omettant une partie de la population. Pour aller plus loin encore dans l’illustration, de nombreuses applications ne considèrent pas les minorités sexuelles : aujourd’hui, on considère que l’on est soit un homme, soit une femme. Qu’en est-il pour les personnes transgenres, intersexes ou même non-binaires ? C’est le vide intersidéral, notamment lorsqu’il s’agit de traitements médicaux grâce aux IA.
Comment ces biais sont-ils remarqués ou relevés ? Ne peuvent-ils pas être détectés plus en amont ?
Aujourd’hui, les erreurs systématiques sont relevées car certaines personnes en sont victimes et dénoncent les manquements. Souvent, on a la très forte impression d’attendre des conséquences potentiellement graves pour analyser le dataset et tester le modèle. C’est ce qu’il s’est passé avec une voiture autonome d’Uber à Tempe (Arizona) qui a tué un piéton. La raison de l’accident s’est révélée après l’enquête : le dataset n’avait pas permis à l’IA d’apprendre à reconnaître les piétons hors des passages cloutés. La victime, qui marchait à côté de son vélo, a été percutée par la voiture qui arrivait trop vite malgré l’identification tardive de la personne comme un piéton. Il faut croire que les questions financières et les retours sur investissements sont plus importants pour ces entreprises que les dégâts que ces IA peuvent causer, par manquement ou négligence.
Existe-t-il une façon pour les expérimentateurs de se prémunir contre ces biais ?
Il existe une seule solution : diversifier les jeux de données au maximum. Est-ce que toutes les populations sont bien représentées par rapport à la réalité ? C’est la question qu’il faudrait se poser à chaque apprentissage, mais il faut penser à toutes les situations donc c’est extrêmement difficile. Si l’équipe chargée d’implémenter l’IA est composée de personnes venant de tous horizons, on peut arriver à limiter les biais. Chacun arrivant avec sa vision des choses, son quotidien et les situations quotidiennement vécues : celui ou celle dont la mère se déplace avec un déambulateur pensera à telle situation ; ou dont le mari est en fauteuil roulant à d’autres ; ceux avec des enfants penseront autrement, etc. Ça n’est pas tant que les modèles conçus contiennent des biais volontaires, mais il y a forcément des minorités auxquelles on pense moins car nous n’en avons pas de représentations dans nos vies quotidiennes. Autre piste, pour éviter que la technologie ne divise encore plus et ne cause plus de dégâts, un brouillon de loi européenne est actuellement en cours de validation. L’Artificial Intelligence Act doit être voté en 2022 pour une application en 2023.
Quelles seront les grandes lignes de ce règlement ?
Cette loi décompose l’utilisation de l’intelligence artificielle selon trois catégories : les « applications interdites » ; les « applications à haut-risque » ; et les « applications à faible risque ». Pour les « applications à haut risque », comme celles utilisées pour l’autorisation de crédit bancaire ou la justice, elles seront soumises à un certificat de conformité CE avant la vente et l’utilisation du modèle. Ces types d’IA seront certainement les plus surveillées car ce sont les plus propices à reproduire des biais discriminants. Cette législation permettra un premier pas vers l’inclusion, je l’espère, en Europe.
La conférence « Jeux de données - biais et impacts sur les femmes dans un monde numérisé » a eu lieu le mercredi 4 mai,
dans le cadre de la semaine des arts et des sciences Queer organisée par l’association étudiante exit+.
[1] Laboratoire Informatique en Images et Systèmes d’Informations
Podcasts « Les cœurs audacieux » - Saison 2 / Épisode 6 - 19 mai 2022

Recherche
« Les rues de la ville où l’on a grandi ont des impacts sur notre cerveau »
Vous avez un mauvais sens de l’orientation ? Certainement la faute à l’endroit où vous avez grandi selon les travaux d’Antoine Coutrot, chercheur CNRS au laboratoire LIRIS1. Dans un récent article paru dans la revue scientifique Nature2, l’équipe de scientifiques énonce une conclusion aux conséquences importantes pour le diagnostic de certaines maladies comme l’Alzheimer : la topologie des routes et rues de la ville influence la cognition humaine. Antoine Coutrot explique comment, à partir d’un jeu vidéo, son équipe et lui ont constaté que les personnes ayant grandi en dehors des villes bénéficiaient d’un meilleur sens de l’orientation. Explications.
Qu’appelle-t-on sens de l’orientation ?
Le sens de l’orientation n’est pas vraiment une capacité cognitive bien identifiée dans le sens où il fait appel à différentes capacités du cerveau comme la proprioception, la vue, l’ouïe et même l’odorat. C’est un sens qui fait partie de « la théorie de l’intelligence fluide », l’esprit logique que l’on a l’habitude de mesurer par des tests de QI, du calcul mental ou la mémorisation par exemple. Lorsque vous naviguez d’un point A à un point B, votre cerveau n’utilise pas qu’un seul réseau de neurones qui serait uniquement consacré à la navigation spatiale, mais plusieurs réseaux différents. Des expériences scientifiques précédentes avaient déjà été réalisées sur des souris et confirmaient l’hypothèse que la topologie de l’environnement dans lequel on a grandi, avait un impact sur ces mêmes réseaux neuronaux. Notre challenge a été de prouver que c’était aussi le cas chez les humains (sans les enfermer dans une cage !)
Par quel moyen avez-vous réussi à démontrer que l’endroit où l’on grandit avait une influence sur le sens de l’orientation que l’on développe à l’âge adulte ?
Les prémices du projet ont débuté en 2016, lorsque j’étais en post-doc à l’University College London. Je travaillais avec une équipe de chercheurs sur la maladie d’Alzheimer dont la perte de sens de l’orientation est un indice important pour le diagnostic. L’un des enjeux principaux de la récolte de nos données d’étude a été de s’assurer d’avoir des profils de personnes d’horizons et de démographies très différentes. Alors nous avons pensé au jeu-vidéo, pour toucher une grande diversité de profils. Plusieurs milliards de minutes de jeu de divertissement sont consommées chaque jour, alors nous pouvions bien en détourner quelques-unes à des fins utiles ! Nous avons donc repris des tests classiques de la littérature scientifique de navigation spatiale pour les rendre plus ludiques ; après plusieurs mois d’échanges avec des concepteurs de jeu, nous avons créé « Sea heroe quest ». Le jeu consiste à mémoriser sur une carte, un itinéraire exact et à le reproduire le plus fidèlement à bord d’un bateau naviguant dans un univers en 3D. Avant de lancer le jeu, nous avons corrélé cette expérience numérique à des exercices du même type « en vrai », avec un échantillon de profils plus restreints pour s’assurer que c’était bien la capacité d’orientation que nous mesurions et non pas la capacité à jouer aux jeux-vidéos. En trois ans, l’application a été téléchargée plus de 4 millions de fois et près de 400 000 joueurs ont accepté de participer à l’expérience. C’est la plus grande base de données connue jusqu’à aujourd’hui sur le sujet.
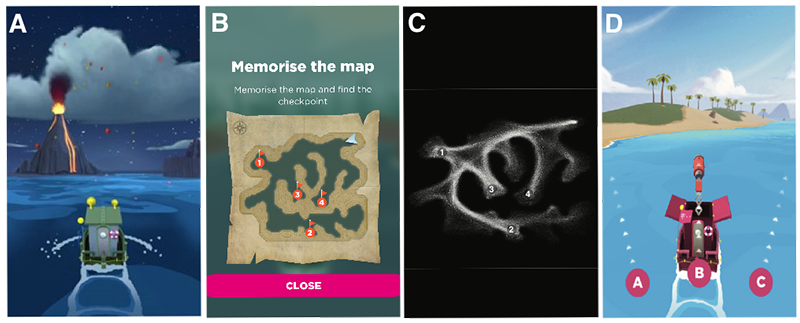
Comment avez-vous poursuivi l’analyse de ces données ?
Nous avons interrogé le sujet sous l’angle de plusieurs prismes : l’âge, le genre et la topologie des villes dans lesquelles on a grandi. Pour l’âge, les données ont démontré que la capacité d’orientation diminuait avec les années. Pour le genre, nous avons conclu que le sens de l’orientation entre les hommes et les femmes évoluaient en fonction de l’égalité des droits3 entre les deux sexes dans le pays ; par exemple, les profils de femmes que la loi n'autorisent pas à conduire ont un sens de l’orientation moins développé que celles qui conduisent. L’étude a surtout montré que les capacités d’orientation des individus sont influencées par leur origine géographique : par exemple, lorsque l’on a grandi dans une ville au maillage de rues complexe, nous avons une meilleure adaptation à s’orienter. Plus la ville de notre enfance est « quadrillée », comme les grandes villes américaines ou argentines, moins notre sens de l’orientation sera bon. Nous allons prochainement étudier l’influence du sommeil et du niveau d’éducation sur le sens de l’orientation.
Concrètement, à quels types d’applications cette découverte pourrait-elle servir ?
D’abord, elle fournit une preuve de l’effet de l’environnement sur la cognition humaine et souligne l’importance de l’aménagement urbain sur la fonction cérébrale. En prenant en compte cela, on pourrait imaginer que les urbanistes construisent des villes qui améliorent le développement cérébral ! En fait, cette base de données est une mine pour de nombreuses recherches de tout ordre ; nous avons d’ailleurs beaucoup de demandes de collaborations. Au-delà, cette recherche aura surtout des conséquences sur ce à quoi elle était destinée : améliorer le diagnostic précoce de l’Alzheimer. La perte de sens de l’orientation était un indice important pour le diagnostic de la maladie, seulement, il n’était pas assez précis car beaucoup de personnes ont un sens de l’orientation peu développé. Désormais d’un point de vue clinique, on pourra considérer différemment les patients ayant grandi dans telle ou telle ville. Les diagnostics préventifs des maladies impliquant les réseaux neuronaux utilisés pour le sens de l’orientation, comme Alzheimer ou les troubles de stress post-traumatique, en seront ainsi améliorés.
[1] Laboratoire d'informatique en image et systèmes d'information (CNRS/INSA Lyon/Université Claude BernardLyon 1/Lyon 2/École Centrale de Lyon)
[2] Coutrot, A., Manley, E., Goodroe, S.etal.Entropy of city street networks linked to future spatial navigationability.Nature604,104–110 (2022). https://doi.org/10.1038/s41586-022-04486-7
[3] Selon le « gender gap report » du World Economic Forum : https://www.weforum.org/reports/global-gender-gap-report-2021